
My Thesis Behind Dappier
As consumers increasingly adopt AI agents like ChatGPT, Dappier's RAG marketplace enables micro data transactions, facilitating the development of the "AI Internet."


In my last article I went into my experience experimenting with ChatGPT and the intuitiveness of the platform from its early days.
“Early tools like ChatGPT-3.5 were groundbreaking, making AI feel approachable and personal. These advancements effectively “personified” artificial intelligence for everyday users, catalyzing the current AI wave.”
ChatGPT's intuitive appeal lies in its resemblance to traditional search engines, yet it surpasses their functionality by delivering contextually relevant answers directly within its chat interface, rather than merely listing website links. This capability enables users to obtain relevant information faster and easier than conventional search methods, establishing ChatGPT and similar Large Language Models (LLMs) as essential consumer technologies.
Earlier versions of ChatGPT were limited by knowledge cutoff dates, restricting their access to the most recent information. However, with the introduction of ChatGPT Search, the model can now access up-to-date data from the web to respond to user queries. Google, which has historically dominated Search, has developed its own LLM, Google Gemini, which integrates with Google's extensive search infrastructure to provide real-time, contextually relevant information.
Regardless of who ultimately wins Search, I believe we are quickly transitioning to an “AI internet” that is powered through LLMs to provide generative AI content that is contextually relevant and personalized to the user. This shift, however, has the ability to disrupt digital content and the way that it has been historically monetized.
What is Dappier? Dappier is at the forefront of the evolving "AI Internet," facilitating seamless transactions between digital publishers and AI agents that utilize online data to respond to user queries. Through Dappier’s Platform, digital content owners can convert their websites and proprietary information into a Retrieval-Augmented Generation (RAG)-ready format. Dappier's Marketplace empowers these digital publishers to monetize their online data on a per-query basis, allowing them to generate revenue as their content is utilized across any AI endpoint.
Dappier was incubated by B20 Labs and raised seed funding from Silverton Partners earlier this year. Here is my thesis behind Dappier and why I have conviction in this business:
The battle between LLMs and digital publishers
How does Dappier fit into the future of the “AI internet”?
Dappier’s GTM strategy
Who is the founding team?
My thesis behind Dappier
1. The battle between LLMs and digital publishers
1a. The Need for Data Scraping
To understand the relationship between LLMs and digital content it’s critical to know how LLMs fundamentally work, which can broadly be broken down into two phases – training and inference.
In the training phase, LLMs are exposed to extensive text data to learn the intricacies of human language, including grammar, context and word relationships. This comprehensive training is essential for their effective application during the inference phase. In the inference phase, LLMs utilize the patterns and knowledge acquired during training to generate human-like text based on new inputs. This phase enables applications such as text completion, translation, and summarization. Having been trained on an extensive and rich data set, LLMs can demonstrate a high degree of understanding of context and nuance across a wide range of topics.
Given the importance of training LLMs on extensive and diverse data, model providers often turn to the web as a rich source of information. The internet offers a vast array of topics, writing styles, and languages, making it an ideal resource for comprehensive language learning. The process of gathering this digital content is known as data scraping, which involves extracting publicly available text from websites, forums, articles, and other online sources. This collected data serves as the foundation for developing effective LLMs and robust inference engines.
1b. Implications of hiQ Labs v. LinkedIn
The legal landscape of data scraping has been complex, with the hiQ Labs v. LinkedIn serving as a significant precedent.
In hiQ Labs v. LinkedIn, hiQ Labs was a data analytics company that specialized in collecting and analyzing publicly available employment information from platforms like LinkedIn. They used this data to predict employee turnover and map workforce skills and offered these insights to businesses. In 2017, LinkedIn issued a cease-and-desist to stop scraping data from LinkedIn’s public profile, arguing that hiQ’s activities violated the Computer Fraud and Abuse Act (CFAA), a U.S. federal law established in 1986 to combat various forms of computer-related offenses including fraud, damage, malware, password trafficking, and extortionate threats. The key issue in this case was whether hiQ’s data scraping met the CFAA’s definition of “exceeds authorized access,” which the CFAA defines as follows:
"The term 'exceeds authorized access' means to access a computer with authorization and to use such access to obtain or alter information in the computer that the accessor is not entitled so to obtain or alter."
In 2019, the Ninth Circuit Court of Appeals ruled in favor of hiQ, determining that accessing publicly available information did not violate the CFAA. The court's justification centered on the interpretation of "exceeds authorized access" under the CFAA. The court reasoned that since the data hiQ accessed was publicly available to anyone with an internet connection, it did not constitute unauthorized access. This interpretation suggested that the CFAA's provisions against unauthorized access were intended to protect private information, not information freely accessible to the public.
However, in 2021, in Van Buren v. United States, the U.S. Supreme Court clarified the scope of the CFAA by interpreting the phrase "exceeds authorized access." The Court held that an individual "exceeds authorized access" only when they access areas of a computer system that are off-limits to them, not when they misuse information they are otherwise permitted to access. This decision narrowed the CFAA's application, focusing on unauthorized access to restricted areas rather than the misuse of accessible information.
Following the Supreme Court's decision in Van Buren v. United States, the Supreme Court vacated the Ninth Circuit's ruling in hiQ Labs v. LinkedIn and remanded the case for reconsideration. In April 2022, the Ninth Circuit reaffirmed its position, concluding that since the data was publicly available, hiQ's access did not constitute unauthorized access under the CFAA, aligning with the Supreme Court's interpretation in Van Buren.
In November 2022, the U.S. District Court for the Northern District of California determined that hiQ Labs breached LinkedIn's User Agreement by scraping data and employing independent contractors to create fake accounts for data collection. The case concluded in December 2022 with a settlement, wherein hiQ agreed to a consent judgment and permanent injunction, effectively ceasing its data scraping activities on LinkedIn's platform.
HiQ Labs v. LinkedIn highlighted that data scraping may violate the CFAA if a company's user agreement explicitly prohibits such activities.
Following the hiQ Labs v. LinkedIn decision, many digital publishers have revised their terms of service to explicitly prohibit data scraping, particularly for training AI models. In 2023, both X (formerly Twitter) and The New York Times updated its terms to forbid the use of its content for AI training without explicit permission. Similarly, in 2024, Reddit announced that companies scraping its data would need to enter into licensing agreements, emphasizing that unauthorized data scraping is not permitted. These actions reflect a broader trend among content providers to protect their digital assets from unlicensed use in AI development.
As digital publishers have amended their terms of use to prevent data scraping, several key lawsuits are in process against model developers that scraped their data to train their LLMs.
In 2023, several AI model developers, including OpenAI (ChatGPT), Google (Gemini), and Anthropic (Claude), faced public and legal allegations concerning copyright infringement and data privacy practices related to their training methodologies. These cases share a common thread – allegations that these companies scraped personal data from the internet without consent to train their AI models, violating copyright laws and user agreements.
The hiQ Labs v. LinkedIn case established that data scraping in violation of a company's user agreement may breach the CFAA. Recognizing the legal implications, AI model providers have increasingly sought licensing partnerships with digital publishers to access content for training their models.
Over the course of this year, OpenAI has partnered with The Associated Press, The Financial Times, and News Corp, granting access to publications such as The Wall Street Journal, Barron's, MarketWatch, and The New York Post. Similarly, in October, Meta secured a multi-year AI content licensing deal with Reuters, enabling Meta's AI chatbot to use Reuters' content to provide real-time answers to users' questions on news and current events.
1c. How would digital publishers be compensated at scale?
While major digital publishers like News Corp and The Associated Press have secured compensation from AI model providers through licensing agreements, smaller digital publishers – such as blogs and forums – face significant challenges to their monetization strategies.
Let’s take a fun example – say that I am going to Mexico City, and I want to find where I can see the best Lucha Libre in Mexico City (fun fact: its Arena Mexico!). Previously, I would Google “Best Lucha Libre in Mexico City” and let Google PageRank find the websites that would be most relevant to my query. When I tried this, one of the first links that pops up is a blog called Matador Network that provides a comprehensive background on what Lucha Libre is, where I can find it, and how I’d go about buying tickets.
Now, I ask the same query through an LLM, such as ChatGPT, which can provide answers based on the data it has been trained on, including information from websites such as the Matador Network blog. With ChatGPT's new search capabilities, it can also perform real-time searches to find upcoming shows and current ticket prices.
Matador Network, however, monetizes its content through banner ads displayed on its website. When users obtain information directly from ChatGPT instead of visiting the blog, it results in fewer page views for the site, leading to reduced advertising revenue. At the same time, Matador Network is not large enough as an organization to navigate its own licensing deal with larger foundational models.
At scale, I believe the only way to ensure that digital publishers are adequately compensated when their data is utilized by an AI system is through a real-time marketplace to support these transactions.
2. How does Dappier fit into the future of the “AI internet”?
Dappier provides both a platform and a marketplace that will facilitate the future of the “AI internet”. I’ve illustrated how Dappier fits into the ecosystem below –
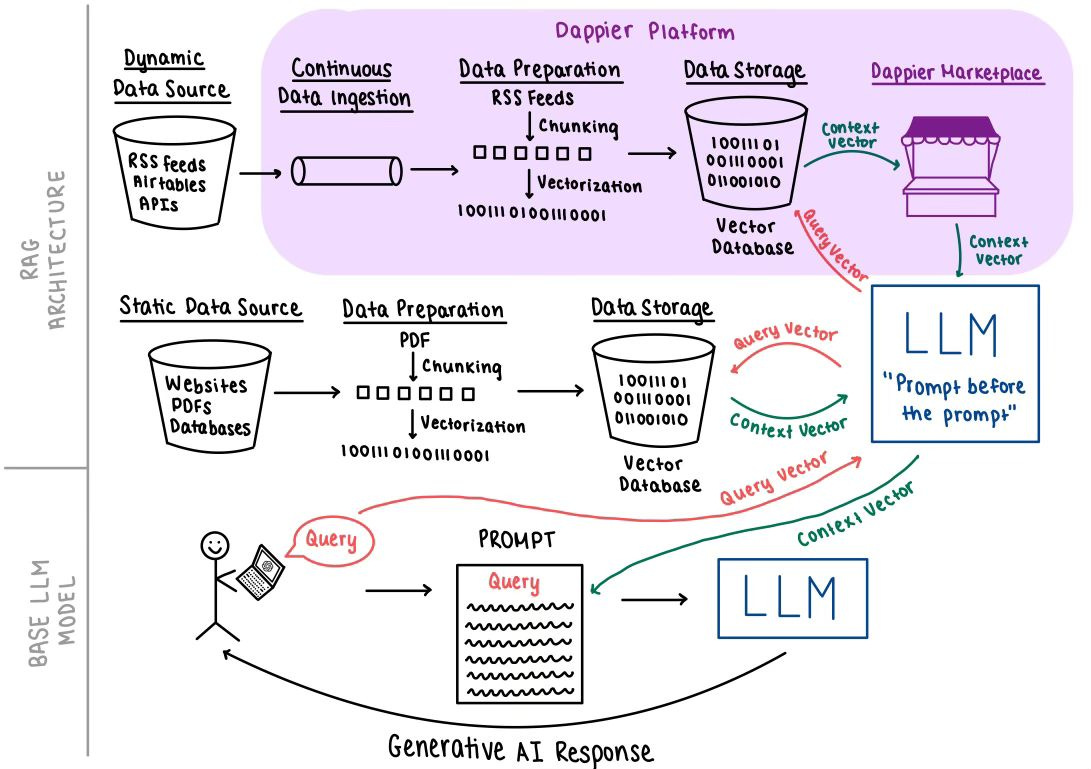
Dappier's system is designed to enable digital publishers to monetize their content across various AI endpoints. Whether a user submits a query through a text-based interface like ChatGPT or a voice-activated assistant, Dappier ensures that publishers receive compensation for the use of their content. This novel approach provides a consistent monetization strategy for publishers, regardless of the platform through which their content is accessed.
In a base LLM setup without RAG, a user’s query is directly input as a prompt to the LLM without additional context. The LLM’s inference engine then generates a response solely based on its pre-existing training data, aiming to address the query using the patterns and information the LLM has learned during the training phase.
LLMs are often enhanced using RAG architectures, especially in enterprise use cases. RAG provides LLMs with additional, relevant context – referred to as the “prompt before the prompt” – to generate more accurate and contextually relevant responses.
RAG incorporates two types of data:
Static Data: This includes fixed information such as PDFs, websites, and proprietary databases, representing data at a specific point in time. Traditional LLMs, like earlier versions of ChatGPT, were trained on such static datasets, leading to limitations in accessing information beyond their training cutoff date.
Dynamic Data: This encompasses continuously updated information from sources like RSS feeds, Airtable, and APIs. Incorporating dynamic data is crucial for responding to queries that require the most current information. Implementing RAG with dynamic data necessitates ongoing data ingestion pipelines to provide real-time context.
Preparing both static and dynamic for use in a RAG architecture involves several key steps:
Data Chunking: The data is divided into smaller, manageable segments, often referred to as "chunks." This segmentation facilitates efficient processing and retrieval.
Vectorization: Each chunk is transformed into a numerical representation known as an embedding. This process captures the semantic meaning of the content, allowing similar pieces of information to have closely related vector representations.
Data Storage: The resulting vectors are stored in a specialized vector database. This setup enables efficient similarity searches, allowing the RAG system to quickly retrieve relevant information based on the user's query
By following these steps, both static and dynamic data are structured in a way that enhances the RAG system's ability to provide accurate and contextually relevant responses.
The beauty of RAG architecture lies in its ability to enhance LLM by integrating relevant external information. When a user submits a query, the system vectorizes it into a numerical representation, known as a query vector. This vector is then compared against a vector database containing pre-processed static and dynamic data to identify the most pertinent pieces of information.
By selecting only relevant data, referred to as context vectors, the system ensures that the LLM receives concise and pertinent information. These context vectors are incorporated into the initial prompt alongside the original query, providing the LLM with enriched context. This approach prevents the LLM from being overwhelmed with excessive data and enables it to generate responses that are both accurate and contextually appropriate, effectively leveraging proprietary data to provide a generative response to the user's question.
Dappier's platform enables digital publishers to seamlessly integrate their website URLs and proprietary data into "RAG-ready" data models within minutes. The platform continuously ingests, integrates, prepares, and stores this data, allowing publishers to list their data models in Dappier's marketplace and set their own price per query.
Let’s go back to our example of finding the best Lucha Libre in Mexico City and see how Matador Network, a travel blog, would be able to monetize their content through Dappier.
When a user submits a query to an AI agent or endpoint, the LLM will seek to provide the most relevant response by leveraging its pre-existing training data or conducting real-time internet searches. To enhance accuracy, the LLM can access Dappier's marketplace, where it utilizes the query vector to identify digital content sources that offer relevant context. If Matador Network's content aligns closely with the query, the LLM can purchase this data through Dappier's marketplace at the price per query set by Matador Network. This acquired information serves as a context vector, enriching the initial prompt and enabling the LLM to deliver a response that incorporates Matador Network's proprietary content.
3. Dappier’s GTM Strategy
While being the marketplace that facilitates the “AI Internet” is Dappier’s long-term vision, their current GTM strategy centers on providing digital publishers with a dual-value proposition – monetization and AI integration.
Through the Dappier Marketplace, publishers can license their proprietary content to AI developers, setting their own prices per query. Additionally, Dappier offers embeddable AI widgets, such as voice and chat agents, that publishers can seamlessly integrate into their platforms to enhance user engagement. This dual-structured GTM strategy extends the value of Dappier’s product beyond merely facilitating micro data transactions. Transforming publishers' proprietary data into a RAG-ready format enables seamless deployment of AI-driven agents on publishers' websites which helps enrich user interactions.
Dappier's GTM strategy has yielded significant traction, with its platform now encompassing digital publishers that collectively reach over 35 million monthly readers.
Dappier has gained significant traction among online digital publishers, notably partnering with The Publisher Desk and Exame, Brazil's leading business magazine since 1967. To monetize these partnerships, Dappier employs a freemium subscription model. All tiers, including the free version, provide access to public data models, customizable personas with fine-tuning capabilities, the RAG marketplace, GPT-3.5 integration, and the ability to upload custom data. Premium subscription tiers offer additional features such as custom data integration, advanced fine-tuning, and deployment of AI agents across customer endpoints like WhatsApp, Telegram, and SMS. Pricing for these tiers ranges from free to $100 per month ($799 annually).
Additionally, Dappier has established strategic partnerships with several omnichannel digital publishers and media companies, enhancing its reach and service offerings.
In October 2024, Dappier partnered with Morgan Murphy Media, a local media company, to revolutionize local media monetization through AI. This collaboration addresses the evolving media landscape where AI queries are becoming the new currency for ad impressions, yet local TV and radio stations have been largely overlooked by foundational AI companies' licensing efforts. Dappier enables legacy TV and radio providers, like Morgan Murphy Media, to proactively define the use of their content in the AI-driven internet, allowing them to take an offensive stance to AI. Similarly, In July 2024, Dappier partnered with HomeLife Brands, the parent company of IHeartDogs and IHeartCats, to monetize their extensive pet-related content for AI applications. With over 40 million followers across social media platforms, HomeLife Brands can now license their vast content library, enabling AI developers to enhance their models with specialized pet knowledge.
Dappier's dual-value proposition and freemium subscription model have enabled it to gain impressive traction among online digital publishers and secure major partnerships with omnichannel media providers.
4. Who is the founding team?
Dappier's leadership team comprises seasoned entrepreneurs with a proven track record of building and successfully exiting companies, with their collective talents uniquely positioning them to execute Dappier's business plan effectively.
Dan Goikhman, Co-Founder and CEO of Dappier, is a seasoned entrepreneur with a proven track record of successful ventures in the technology and media sectors. In 2014, he and Krish co-founded Mojiva, a pioneering mobile ad network that was acquired by PubMatic. Subsequently, in 2022, he led Powr.tv, a Connected TV (CTV) publishing platform, to its acquisition by Bitcentral. Dan's extensive experience in strategic partnerships and revenue generation, coupled with his leadership in bridging technology and media, is instrumental in steering Dappier's vision and growth.
Krish Arvapally, Co-Founder and Chief Technology Officer, is a serial tech entrepreneur with two successful exits. In addition to co-founding Mojiva with Dan, he also co-founded Unreel, an over-the-top (OTT) video streaming platform, which was acquired by Powr.tv in 2019. Recognized as a pioneer in ad tech and Connected TV (CTV) streaming, Krish's technical expertise and innovative approach are pivotal in developing Dappier's cutting-edge platform.
Akshay Arvapally, Co-Founder and Head of Product, is a seasoned entrepreneur with a strong background in technology and media. As President of Powr.tv, Akshay led the company to a successful acquisition by Bitcentral in 2022, demonstrating his ability to drive growth and innovation in the OTT streaming industry. His deep understanding of product development and market dynamics ensures that Dappier's offerings are both user-centric and market-relevant.
Collectively, this team combines extensive experience in entrepreneurship and the media industry, technology innovation, product development, and strategic partnerships. Their combined expertise positions Dappier to effectively execute its business plan and drive innovation in the “AI Internet”.
5. My thesis behind Dappier
Dappier is well-positioned to be a key player in the emerging "AI Internet" by enabling essential micro data transactions that support AI-driven applications.
The legal landscape surrounding data scraping is complex, with several on-going court cases currently shaping its future. The precedent set by hiQ Labs v. LinkedIn suggests a narrower interpretation of the CFAA's "exceeds authorized access" clause, while the ability for digital publishers to restrict data scraping through updated terms of use implies that, eventually, all data in the AI ecosystem may need to be licensed. This trend is further evidenced by foundational AI providers recently establishing data licensing agreements with content creators. Effectively managing these partnerships across the amount of digital content available on the internet, however, necessitates a real-time marketplace. From what I’ve seen, no other platforms currently facilitate these micro data transactions, positioning Dappier to fill this critical and inevitable gap.
One of the reasons why AI engineers have not developed a centralized marketplace for these AI data transactions may stem from the assumption that model providers would eventually establish such platforms. This perspective might hold if the AI model landscape mirrored Search, where a single entity like Google dominates. However, the current AI ecosystem is characterized by multiple LLMs such as ChatGPT, Gemini, and Claude which are leveraged in different aspects of the AI ecosystem. Consequently, no single entity governs the "AI Internet." This decentralization creates an opportunity for marketplaces like Dappier to become facilitators of the “AI Internet”.
Lastly, the Dappier team is a battle-tested group of serial entrepreneurs that have successfully led multiple exits, and I have a strong belief in their vision and ability to execute on this business plan.
Thanks for making it all the way to the end! If you have any thoughts, questions, or feedback, I'd love to hear them – your input is always valuable.